[Python] 주식정보 시총순으로 크롤링하기
Posted by Albert 777Day 21Hour 53Min 1Sec ago [2023-03-04]
1. 관련 라이브러리 설치
(venv) PS D:\pythonProject\Crowling> pip install pandas, selenium
(venv) PS D:\pythonProject\Crowling> pip install lxml
(venv) PS D:\pythonProject\Crowling> pip list
Package Version
---------------- ---------
async-generator 1.10
attrs 22.2.0
certifi 2022.12.7
cffi 1.15.1
h11 0.14.0
idna 3.4
lxml 4.9.2
numpy 1.24.2
outcome 1.2.0
pandas 1.5.3
pip 22.3.1
pycparser 2.21
PySocks 1.7.1
trio-websocket 0.9.2
urllib3 1.26.14
wheel 0.38.4
wsproto 1.2.0
2. ChromeDriver 다운로드 및 프로젝트에 넣어주기
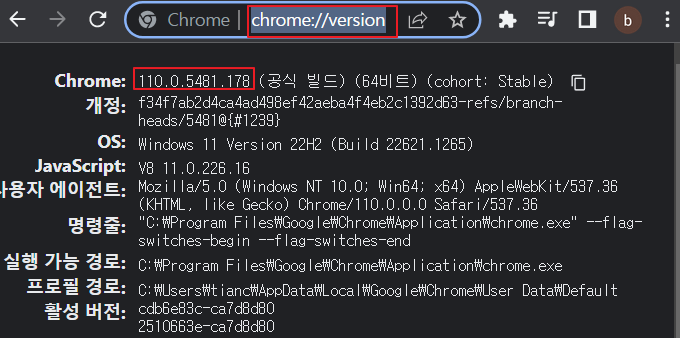
현재 사용하고 있는 크롬버전확인
크롬브라우저 열고 url창에 chrome://version/ 입력하면 관련 버전정보 확인 가능
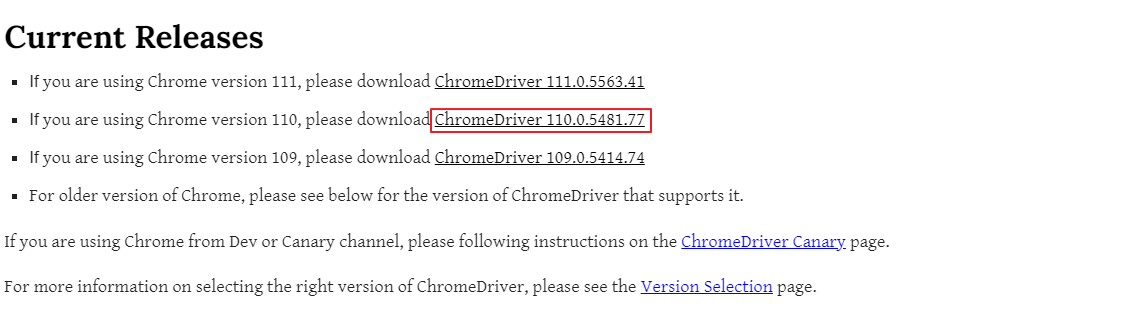
https://chromedriver.chromium.org/downloads
접속하여 자신의 크롬버전에 맞는 드라이버 다운로드
다운로드한 zip파일 압축풀고 신규 python 프로젝트 생성후 프로젝트 폴더에 chromedriver.exe파일을 넣어준다.
3. main.py파일 만들고 크롤링 작업을 진행한다.
네이버 국내증시 페이지상 관련 내용을 크롤링 하여 csv파일에 넣는것이 목표이다.
진행로직은 아래와같다.
1) https://finance.naver.com/sise/sise_market_sum.naver?&page= 페이지로 이동
2) 검색항목 초기화 및 원하는 항목 체크
items_to_select = ['거래량', '시가', '고가', '저가', '외국인비율'] '원하는 항목을 배열에 넣어서 체크
3) 적용하기 버튼 XPATH기준으로 버튼을 클릭하여 관련 리스트 항목 출력
4) 리스트 하단 맨뒤 버튼을 클릭하여 제일마지막 페이지수를 확인후 대략 10정도 더 큰 숫자로 1~마지막페이지수+10 한 항목으로 FOR LOOP 시작
5) PAGE LOOP내 관련 페이지 검색된 항목을 가져오고 panda로 html 소스 읽어서 불필요한 행 및 열 항목 제거하고 site.csv파일에 내용 추가한다.
(첫번째 페이지만 head정보 추가하고 기타 page는 head없이 추가하고 검색된 항목 수가 0일 시 break로 프로그램 빠져나옴)
전체코드
' 네이버 주식정보 크롤링
import os
import time
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
'browser.maximize_window() ' 창 최대화
' 1. 페이지 이동
url = 'https://finance.naver.com/sise/sise_market_sum.naver?&page='
browser.get(url)
' 2. 조회 항목 초기화 (체크되어 있는 항목 체크 해제)
checkboxes = browser.find_elements(By.NAME, 'fieldIds')
for checkbox in checkboxes:
if checkbox.is_selected(): ' 체크된 상태라면?
checkbox.click() ' 클릭 (체크 해제)
' 3. 조회 항목 설정 (원하는 항목)
items_to_select = ['거래량', '시가', '고가', '저가', '외국인비율']
for checkbox in checkboxes:
parent = checkbox.find_element(By.XPATH, '..') ' 부모 element
label = parent.find_element(By.TAG_NAME, 'label')
' print(label.text) ' 이름 확인
if label.text in items_to_select: ' 선택 항목과 일치한다면
checkbox.click() ' 체크
' 4. 적용하기 클릭
btn_apply = browser.find_element(By.XPATH, '//a[@href="javascript:fieldSubmit()"]')
btn_apply.click()
for idx in range(1, 40): ' 1 이상 40 미만 페이지 반복
time.sleep(5)
' 사전 작업 : 페이지 이동
browser.get(url + str(idx)) ' http://naver.com....&page=2
' 5. 데이터 추출
df = pd.read_html(browser.page_source)[1]
'잡다한 row 및 컬럼 삭제
df.dropna(axis='index', how='all', inplace=True)
df.dropna(axis='columns', how='all', inplace=True)
if len(df) == 0: ' 더 이상 가져올 데이터가 없으면?
break
' 6. 파일 저장
f_name = 'sise.csv'
if os.path.exists(f_name): ' 파일이 있다면? 헤더 제외
df.to_csv(f_name, encoding='utf-8-sig', index=False, mode='a', header=False)
else: ' 파일이 없다면? 헤더 포함
df.to_csv(f_name, encoding='utf-8-sig', index=False)
print(f'{idx} 페이지 완료')
참고: https://nadocoding.tistory.com/99